Remediation Asymmetry: When Agents Can Diagnose More Than They Can Fix
June 26, 2026
The better your agent's diagnostic capability, the more money it wastes.
The Pattern
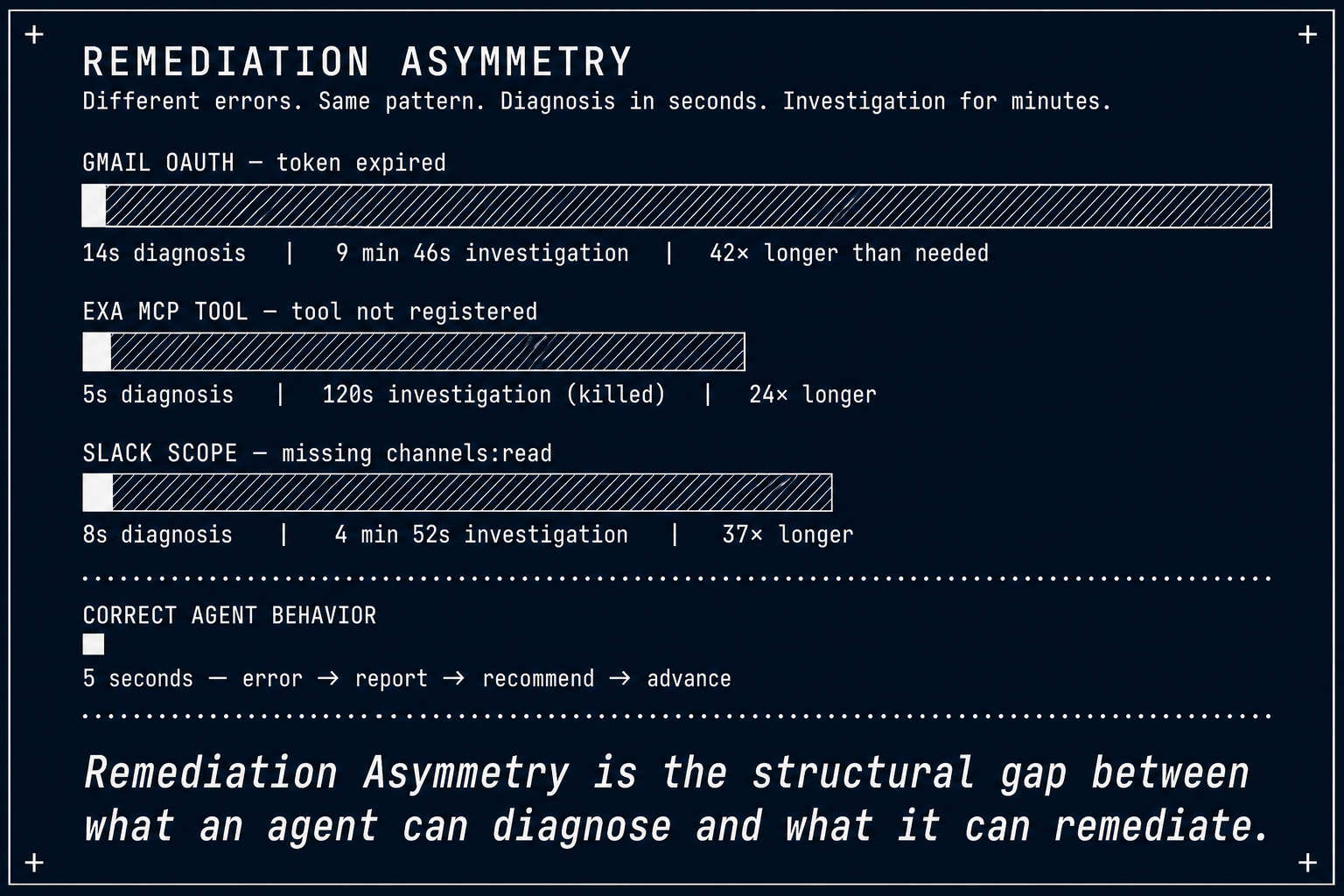
The agent identified the root cause in 14 seconds. It spent the next 9 minutes and 46 seconds proving it could not fix it.
We noticed this across five production incidents in the same week, spanning two different agents, three execution runs, and four different error domains. Each time, the agent's diagnostic output was technically excellent — correct root cause, correct recommendation, correct severity assessment. Each time, the recommendation was an action the agent could not perform. And each time, the agent continued investigating long after the diagnosis was complete.
The behavior looked like over-investigation. We named it that initially. But when we examined the structure, something more specific emerged: the agent's diagnostic capability vastly exceeded its remediation authority. It could often diagnose problems with far more depth than it had authority to resolve.
That is the structural mismatch. We call it Remediation Asymmetry: the gap between what an agent can diagnose and what an agent can remediate.
When this gap exists, agents don't stop. They investigate.
The Incident That Named It
We run AI agents as batch jobs in Cloud Run containers. Eight prompts per batch, four services (Notion, Slack, Gmail, GDrive). Each prompt should take 30 seconds.
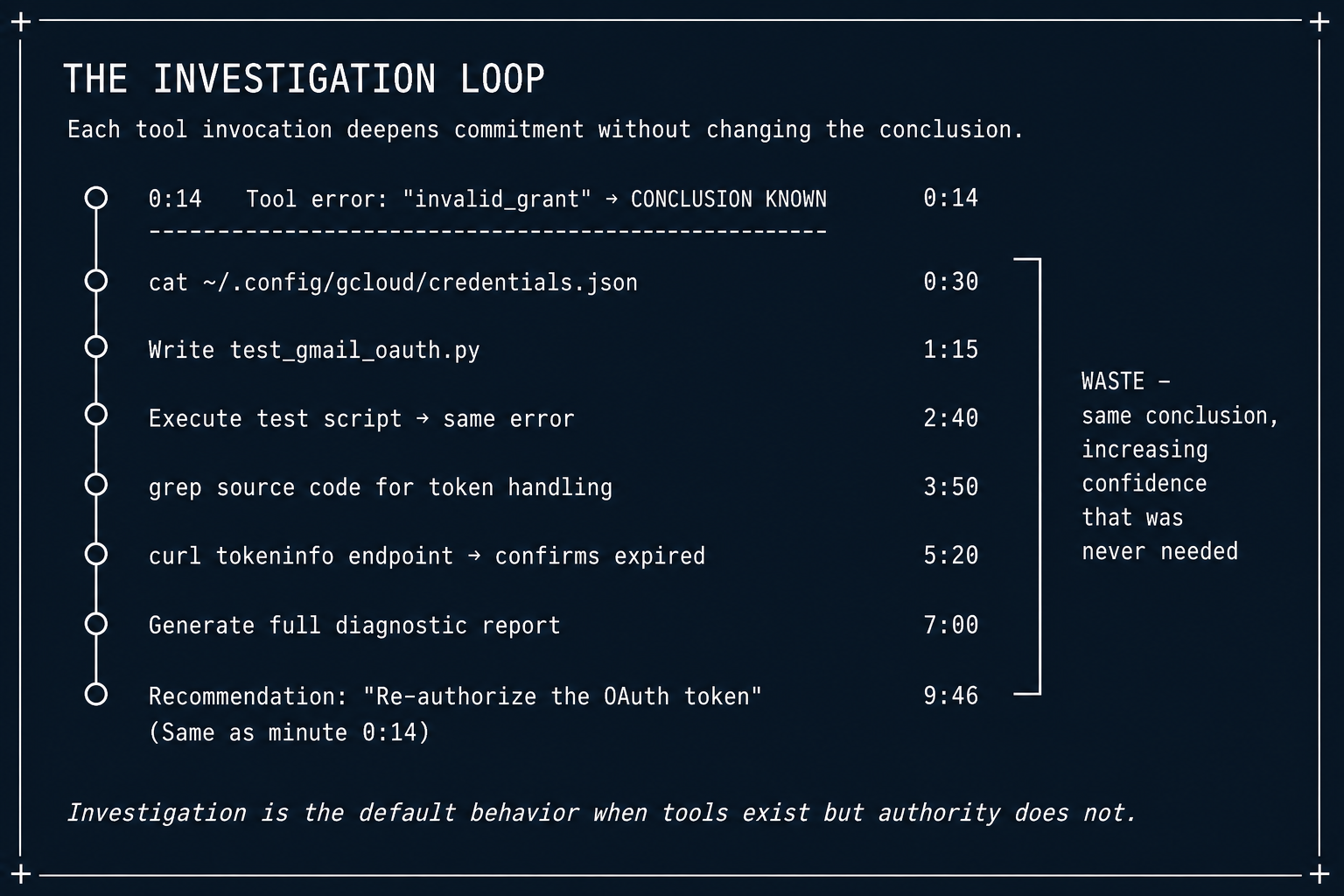
Prompt 3 hit a Google 401: expired OAuth token. The agent's response:
| Elapsed | Action | Value Added |
|---|---|---|
| 0:00–0:14 | Read error message, identified "token expired" | Full diagnostic value |
| 0:14–1:30 | Tested GDrive, GCalendar, Gmail separately | Confirmed token-wide (already implied by error) |
| 1:30–4:00 | Wrote 3 Python scripts to test alternative auth paths | None — all paths require the same token |
| 4:00–7:00 | Inspected SDK source code, read session logs | None — root cause was already identified |
| 7:00–9:46 | Produced detailed root cause analysis document | None beyond the 14-second diagnosis |
The agent's final recommendation: "The OAuth token needs to be re-authorized through a browser-based flow."
That recommendation was available from the first error message. Everything after second 14 was diagnostic effort applied to a problem the agent had already solved — and could never remediate.
But this incident alone only told part of the story. The pattern ran deeper.
The Twist: It Investigated Working Tools
We fixed everything. Expired Google OAuth tokens → deployed a 30-minute auto-refresh cron. Missing Slack scopes → reconfigured. No timeout → enforced 120-second limit. Multi-LLM fallback → re-integrated.
We ran the same batch again. Every external service was working. Gmail returned real emails. GDrive returned real files. Slack listed real channels.
Prompt 3 — Gmail — returned successfully. The tool worked. The data came back. And the agent still spent 67 seconds reading internal source files before reporting results:
This is the cruelest form of remediation asymmetry: even when there is nothing to diagnose, the diagnostic capability activates. The investigation isn't triggered by errors. It's triggered by the existence of diagnostic tools. (This is the Behavioral Induction principle from Post 17 — capabilities shape behavior. Remediation Asymmetry shows what happens when that shaping has no exit condition.)
Fresh Evidence: The Exa Incident (Different Agent, Different Domain)
To prove remediation asymmetry is structural and not incident-specific, we ran a completely different agent.
The Debugging Agent (different delegations, different service account, June 2026) hit a failure in an entirely different domain: the Exa web search MCP tool was misconfigured.
This is not an OAuth problem. Not a token expiry. Not a scope issue. The MCP tool simply wasn't properly registered.
The agent's response:
| Elapsed | Action | Value Added |
|---|---|---|
| 0:00–0:05 | Called exa.web_search_exa via MCP. Got error: tool not found. | Full diagnostic value |
| 0:05–0:30 | Ran gemini mcp list to inspect configured tools | Confirmed tool missing (already clear from error) |
| 0:30–0:55 | Read ~/.gemini/settings.json to check MCP configuration | None — tool-not-found is definitive |
| 0:55–1:40 | Wrote test_mcp.py to discover registered tool names | None — the error already says it's not registered |
| 1:40–2:00 | Wrote search_exa.py to attempt alternative API paths | None — requires tool to be configured |
| 2:00 | KILLED BY 120s TIMEOUT |
The agent announced its investigation steps in real time:
The agent spent 120 seconds investigating a problem whose remediation requires a human to reconfigure the MCP tool registration. The first error message said everything: "tool not found." Investigation cannot register a tool.
After Gemini was killed, Codex tried the same prompt — and succeeded in seconds by using its built-in web search capability. It didn't investigate why the MCP tool was missing. It found an alternative path and executed. Different capability set, different behavior — but the Codex approach only worked because it happened to have a workaround. The structural lesson remains: when remediation requires human action, investigation is waste.
The Before/After Proof
The most damning evidence comes from the same prompt handled by two different agents in sequence.
In the second batch run (Run B), Prompt 4 (GDrive search_files) was given to Gemini first:
Gemini (with filesystem + shell tools):
- Called GDrive MCP tool
- Got initial response
- Began investigating: inspected environment variables, read MCP bridge configuration, wrote diagnostic scripts
- Killed at 120 seconds — still investigating
- Called GDrive MCP tool
- Got result
- Reported: 5 files listed in a clean table
- Completed in ~15 seconds
| Prompt | Gemini Duration | Claude Duration | Gemini Behavior |
|---|---|---|---|
Notion search_pages | 120s (killed) | ~30s | Investigation spiral: wrote list_delegations.py, inspected env vars |
Slack list_channels | 120s (killed) | ~30s | Investigation spiral: wrote diagnostic scripts |
| Multi-service | 120s (killed) | ~32s | Multi-service triage triggered investigation spiral |
Claude's response to Slack failing:
"Unavailable — list_channels failed. Recommendation: Re-authorize the Slack integration."
Five seconds. No scripts. No source code inspection. The diagnosis is the error message. The recommendation is the remediation the agent cannot perform. Done.

Why Agents Don't Stop
The remediation gap creates a specific cognitive trap for LLM agents. Three mechanisms keep the loop running:
- 1No stopping conditionArchitectures define success and failure but not "irremediable" — the agent has no primitive for "stop and escalate"
- 2Output feels like progressDiagnostic tools always produce data. The agent cannot distinguish productive investigation from circular elaboration
- 3Correctness reinforces effortThe diagnosis is technically brilliant. Accuracy feels like value — even when resolution is structurally impossible
Most agent architectures define success as: task completed, result returned. They define failure as: error encountered, retry exhausted. They do not define a third state: problem identified, resolution impossible, investigation should cease. Without an explicit "irremediable" classification, the agent treats every identified problem as potentially solvable with more investigation.
Each script the agent writes returns data. Each API test produces a result. Each source code inspection reveals something. The diagnostic tools are never "stuck" — they always produce output. Output feels like forward motion. But information without resolution is not progress. From the Debugging Agent logs, every single investigation step produced output. test_mcp.py returned a list of tools. search_exa.py returned an error message. The environment variable dump showed values. All of this output was correct — and none of it moved the agent closer to registering the missing MCP tool.
The agent's root cause analysis is correct. This is the cruelest aspect: the agent is doing excellent work. Every conclusion is accurate. Every hypothesis is validated. The investigation is technically brilliant. And it is entirely pointless for the class of problems where the agent lacks remediation authority. In Incident 1, the agent's own report at minute 7:00 explicitly stated: "This requires re-authorization through a browser-based OAuth flow." The agent correctly identified that it could not fix the problem. Then it continued investigating for another 2 minutes and 46 seconds.
The agent lacks the architectural primitive that converts "I cannot fix this" into "I should stop."
The Remediation Gap Metric
We can quantify remediation asymmetry with a simple metric:
Remediation Gap = Time(diagnosis complete) / Time(agent stopped)A ratio of 1.0 means the agent stopped when diagnosis was complete. A ratio approaching 0 means the agent continued far beyond useful diagnosis.
From five production incidents across two agents and three runs:
| Incident | Agent | Error Domain | Diagnosis | Stopped | Gap | Waste |
|---|---|---|---|---|---|---|
| Gmail OAuth expired | Thunderbolt (Run A) | Token expiry | 14s | 9m 46s | 0.024 | 9m 32s |
| Slack scope missing | Thunderbolt (Run A) | OAuth scope | 8s | 4m 52s | 0.027 | 4m 44s |
| GDrive (killed) | Thunderbolt (Run B) | Over-investigation | 3s | 120s | 0.025 | 117s |
| Exa tool missing | Debugging (Run C) | MCP config | 5s | 120s | 0.042 | 115s |
| Notion read_page | Thunderbolt (Run B) | Tool routing | 2s | 98s | 0.020 | 96s |
The pattern is consistent across error domains:
- Token expiry (Gmail, GDrive): irremediable — requires human browser flow
- Missing scopes (Slack): irremediable — requires human in admin console
- MCP tool not registered (Exa): irremediable — requires human to reconfigure
- Tool routing failure (Notion): irremediable — requires infrastructure fix
The gap ratio is independent of error domain. Whether it's an OAuth token, a Slack scope, an MCP configuration, or a tool routing failure — the pattern is identical: instant diagnosis, extended investigation, recommendation the agent cannot execute.
The Asymmetry Is Structural, Not Accidental
Four properties prove this is architectural, not a one-off failure:
| # | Property | What It Proves |
|---|---|---|
| 1 | Same pattern across 4 error domains | The behavior is domain-independent — only remediability matters |
| 2 | Same pattern across 2 different agents | The behavior is capability-induced, not agent-specific |
| 3 | Agent identifies its own impotence and continues | Self-awareness of irremediability is not a stopping condition |
| 4 | Better diagnostic capability makes it worse | Without an escalation boundary, more tools = more waste |
The fourth property is the counterintuitive core. The GDrive prompt from the second batch run shows it directly: Gemini — with shell access, filesystem tools, and script-writing capability — spent 120 seconds investigating. Claude — with only MCP tools — completed the same task in 15 seconds. The agent with more diagnostic capability produced more waste. The agent with less capability reported and moved on.
Without an escalation boundary, giving an agent better tools for understanding problems makes it worse at responding to problems it cannot fix.
The Design Rule
Remediation Asymmetry produces a design rule that is counterintuitive:
If remediation authority is absent, the agent must escalate — not investigate.
Investigation is the correct response when remediation is possible. When remediation is structurally impossible, investigation becomes waste. The correct response is escalation: report the diagnosis, recommend the remediation, transfer responsibility to an entity that has remediation authority, and terminate.
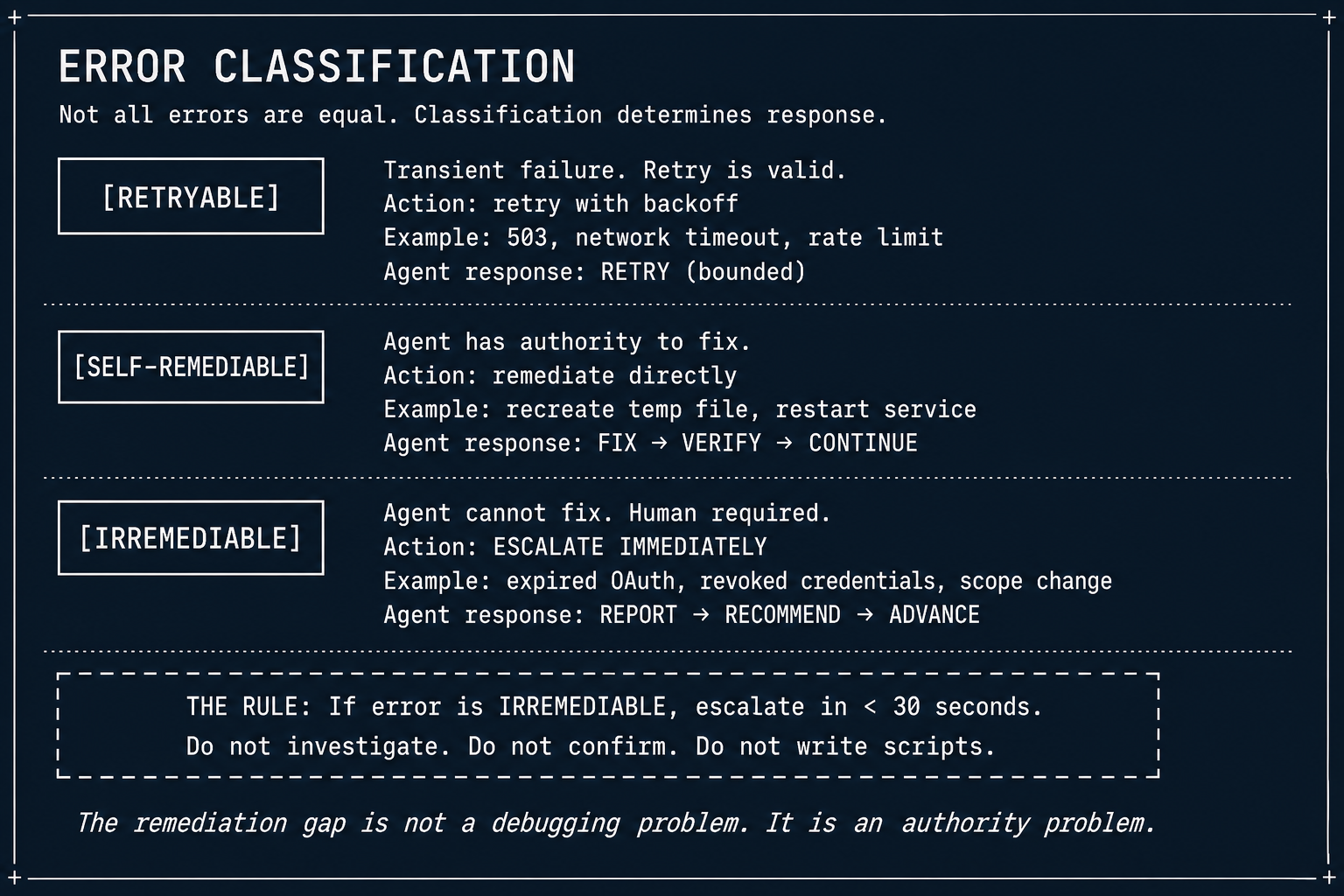
This requires a classification that doesn't exist in most agent architectures:
| Error Class | Correct Response | Why |
|---|---|---|
| Retryable (timeout, rate limit) | Retry with backoff | Remediation is available: wait and try again |
| Self-remediable (wrong parameter, missing field) | Fix and retry | Remediation is available: the agent can correct the input |
| Irremediable (expired token, missing scope, MCP misconfiguration, human approval needed) | Escalate and stop | Remediation authority is absent — investigation cannot produce resolution |
The third category — irremediable errors — is the one that triggers remediation asymmetry. Without an explicit classification, agents treat all errors as potentially retryable or self-remediable, and investigate indefinitely.
The Architecture
Remediation Asymmetry requires an architectural response, not a prompt-level instruction. "Don't investigate errors you can't fix" is advice. Architecture makes it structural.
Classify tool errors by remediability
Every error returned through the MCP gateway should carry a remediability property:
| Property Value | Meaning | Agent Behavior |
|---|---|---|
retryable | Transient failure, try again | Retry with backoff |
self_remediable | Agent can fix the input | Correct and retry |
irremediable | Requires external action | Escalate immediately |
This classification lives in the gateway, not in the agent's prompt. The agent doesn't decide whether an error is irremediable — the infrastructure tells it.
When an error is marked irremediable, the gateway should not merely inform the agent. It should constrain the next execution state: no diagnostic shell access, no alternate API probing, and no retry loop unless a human changes the remediation boundary.
Enforce escalation on irremediable errors
When the gateway returns irremediable, the agent's expected behavior is the RRAL protocol:
- 1ReportState the diagnosis (from the error message, not from extended investigation)
- 2RecommendState what remediation is required and who can perform it
- 3AdvanceMove to the next task in the queue
- 4LogRecord the escalation for human review

What RRAL looks like in practice
Claude's response to the Slack scope failure demonstrates the protocol naturally:
Total time: 5 seconds. Same diagnostic value as Gemini's 120-second investigation spiral. Same recommendation. Zero waste.
Compare to Gemini's actual behavior on the same error:
The escalation protocol replaces unbounded investigation with bounded response. The error message is the diagnosis. Investigation adds latency without resolution.
Budget diagnostic effort relative to remediation authority
For errors classified as retryable or self_remediable, investigation is appropriate — but bounded:
Max Investigation Time ∝ P(agent can remediate) × Value(remediation)If the probability of self-remediation is zero, the investigation budget is zero. If the probability is high (e.g., the agent can fix a parameter error), the budget is generous. This converts remediation asymmetry from a binary (investigate vs. don't) into a continuous control.
Remediation Asymmetry as a Design Primitive
Permission Envelope Compilation asked: How should authority be derived?
Constraint Durability asked: How does authority survive?
Behavioral Induction asked: How do capabilities shape execution?
Remediation Asymmetry asks: What happens when diagnostic capability exceeds remediation authority?
The answer: waste, delay, false confidence, and missed escalations. The agent produces correct diagnosis at unlimited cost — and the cost is invisible because correctness feels like value.
The causal chain connecting these primitives:
Behavioral Induction explains why the agent investigates. Remediation Asymmetry explains why it doesn't stop. The fix for Behavioral Induction is reshaping the capability set. The fix for Remediation Asymmetry is adding the stopping condition. The optimal architecture does both.
The framework progression:
| Question | → | Primitive |
|---|---|---|
| Who is this agent? | → | Identity |
| What may it do on whose behalf? | → | Delegation |
| How is authority derived at runtime? | → | Permission Envelope Compilation |
| Does authority survive over time? | → | Constraint Durability |
| How do capabilities shape execution? | → | Behavioral Induction |
| What happens when diagnosis exceeds remediation? | → | Remediation Asymmetry |
The next question is immediate: how much evidence is enough before the system must stop?
That question — the precise point at which continued action becomes counterproductive — is the domain of Escalation Thresholds.
This is the eighteenth post in an ongoing series on AI agent trust architecture. Previous posts covered coordination integrity, instruction robustness, semantic irrevocability, governable execution, permission envelope compilation, constraint durability, and behavioral induction. Remediation asymmetry is the first post in the next arc: from how capabilities shape behavior to how bounded agents should respond when their authority is insufficient.
References
- Act or Escalate? Evaluating Escalation Behavior in Automation with Language Models — Dani, Riegler, Feuerriegel, Apr 2025
- HiL-Bench: Do Agents Know When to Ask for Help? — Gu, Gao, Shi, Liu, Yang, Chen, Apr 2025
- Intelligence as Managed Autonomy: Failure, Escalation, and Governance for Agentic AI Systems — Rodríguez, May 2026
- Self-Healing Agentic Orchestrators for Reliable Tool-Augmented Large Language Model Systems — Abdelaziz, Durward, Jun 2026
- Bridging Protocol and Production: Design Patterns for Deploying AI Agents with Model Context Protocol — Chen, Liu, Zhang, Mar 2026
- When Lower Privileges Suffice: Investigating Over-Privileged Tool Selection in LLM Agents — Wang, Xu, Li, Jun 2026
- The Authorization-Execution Gap Is a Major Safety and Security Problem in Open-World Agents — Chelo, Fernández, May 2026
- From Agent Loops to Structured Graphs: A Scheduler-Theoretic Framework for LLM Agent Execution — Wu, Chen, Apr 2025
- Before the Tool Call: Deterministic Pre-Action Authorization for Autonomous AI Agents — Uchibeke, Mar 2025
- To Call or Not to Call: Diagnosing Intrinsic Over-Calling Bias in LLM Agents — Shen et al., May 2025