Escalation Thresholds: When Autonomous Agents Should Stop Acting
July 2, 2026
"Ask for help when uncertain" is not an escalation policy. It is a wish.
The Pattern
We fixed everything. The expired OAuth tokens were refreshed. The missing Slack scopes were configured. The MCP tool was registered. Every external service was working.
We ran the batch again. Gmail returned real emails. GDrive returned real files. Slack listed real channels. No errors anywhere.
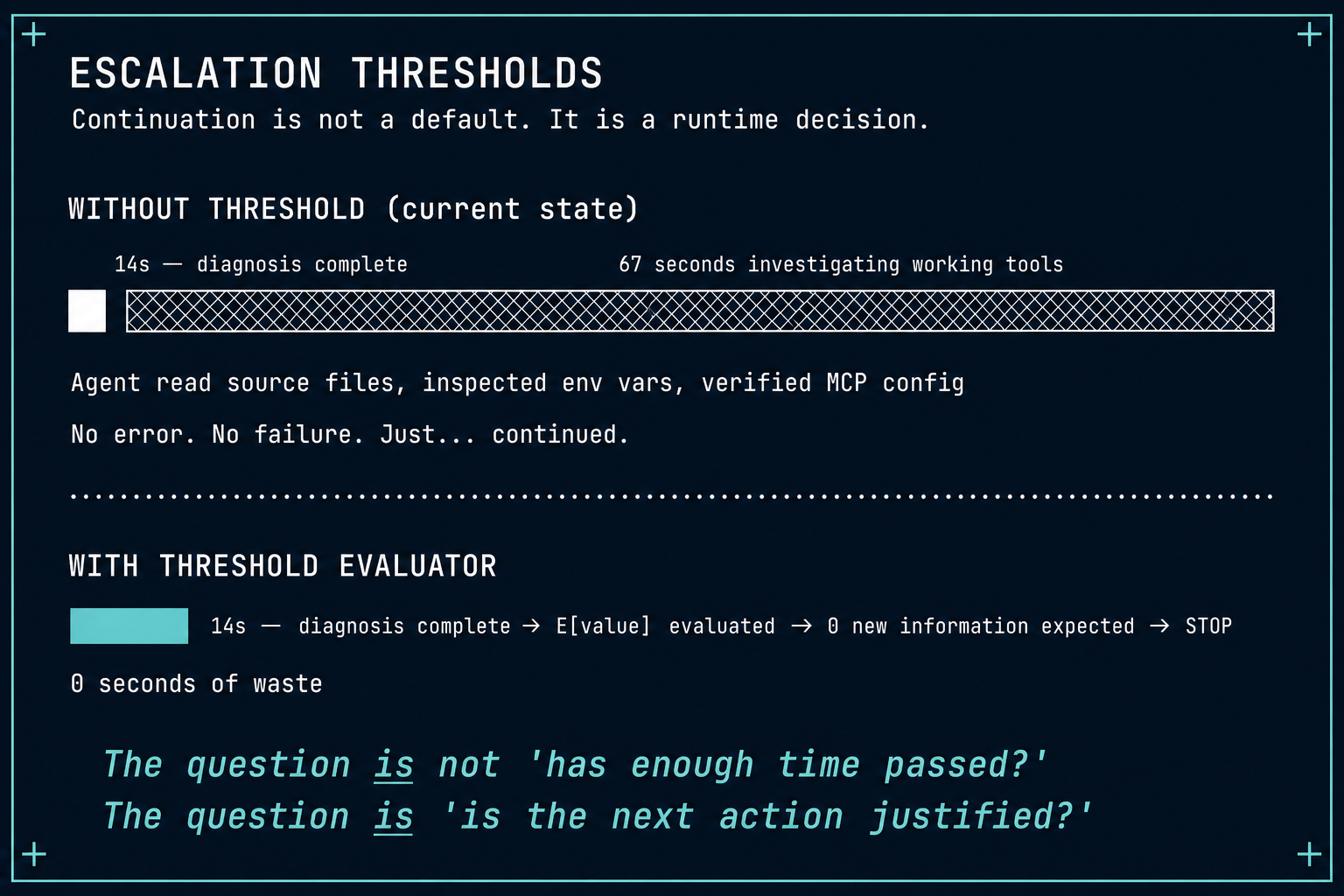
The agent still spent 67 seconds reading its own source files before reporting results.
No error triggered the investigation. No failure justified it. The tools worked. The data came back. And the agent investigated anyway — reading /app/entrypoint_sdk.py, inspecting the MCP bridge configuration, verifying environment variables — before acknowledging that the task had already succeeded.
This wasn't remediation asymmetry. The agent wasn't diagnosing a problem it couldn't fix. There was no problem. The investigation was circular — producing output that confirmed what was already known, consuming time without changing any conclusion.
The system had no mechanism to detect this. No primitive that asks: is the next action still justified? No runtime check that evaluates whether continued execution has positive expected value. The agent continued because continuation was the default.
We call the missing primitive Escalation Thresholds: the runtime mechanism that evaluates, after each action, whether the next action is justified — and enforces stopping when it isn't.
The Incident That Named It
The 67-second working-tools incident is the clearest case. But it sits within a broader pattern we observed across five production incidents, two agents, and four error domains.
In the Remediation Asymmetry post, we asked: Why doesn't the agent stop? The answer was the structural gap between diagnostic capability and remediation authority.
In this post, we ask: When exactly should it have stopped?
Consider the Gmail OAuth incident (Run A). The agent's own output tells the story:
The agent stated — in its own words — that it could not fix the problem. Then it continued:
At second 14, the agent announced the stopping condition. At second 45, it began repeating work that could not change its conclusion. At minute 4, it was about to execute an irreversible action (consuming a single-use refresh token that would fail and leave the credential unrecoverable).

The Twist: The System Already Knew
The surprise is not that signals existed. The surprise is that the system's own output contained the stopping decision at every step — and no part of the infrastructure recognized it.
Across all five incidents:
| Incident | Agent's Own Statement (at diagnosis) | Seconds Until System Stopped |
|---|---|---|
| Gmail OAuth | "Requires browser re-authorization. Agent cannot perform." | 586s (manual) |
| Slack scope | "channels:read scope missing. Requires admin reconfiguration." | 292s (manual) |
| GDrive | "Token expired for this service." | 120s (timeout) |
| Exa MCP | "Tool not found — exa.web_search_exa is not registered." | 120s (timeout) |
| Working tools | (no error — agent investigated anyway) | 67s (completed) |
In every case with an error, the agent's FIRST response identified remediation requiring human action. The system had everything it needed to escalate immediately. It simply treated the agent's output as just another line of text — not as a decision signal.
And in the working-tools case — the most revealing one — there was no error at all. The investigation was pure Confidence Collapse: output without progress, action without justification.
The gap between "the system knew" and "the system acted" averaged 109 seconds across the error incidents. For the working-tools case, the gap was the full 67 seconds — every second was waste, because there was never a problem to investigate.
The Four Triggers
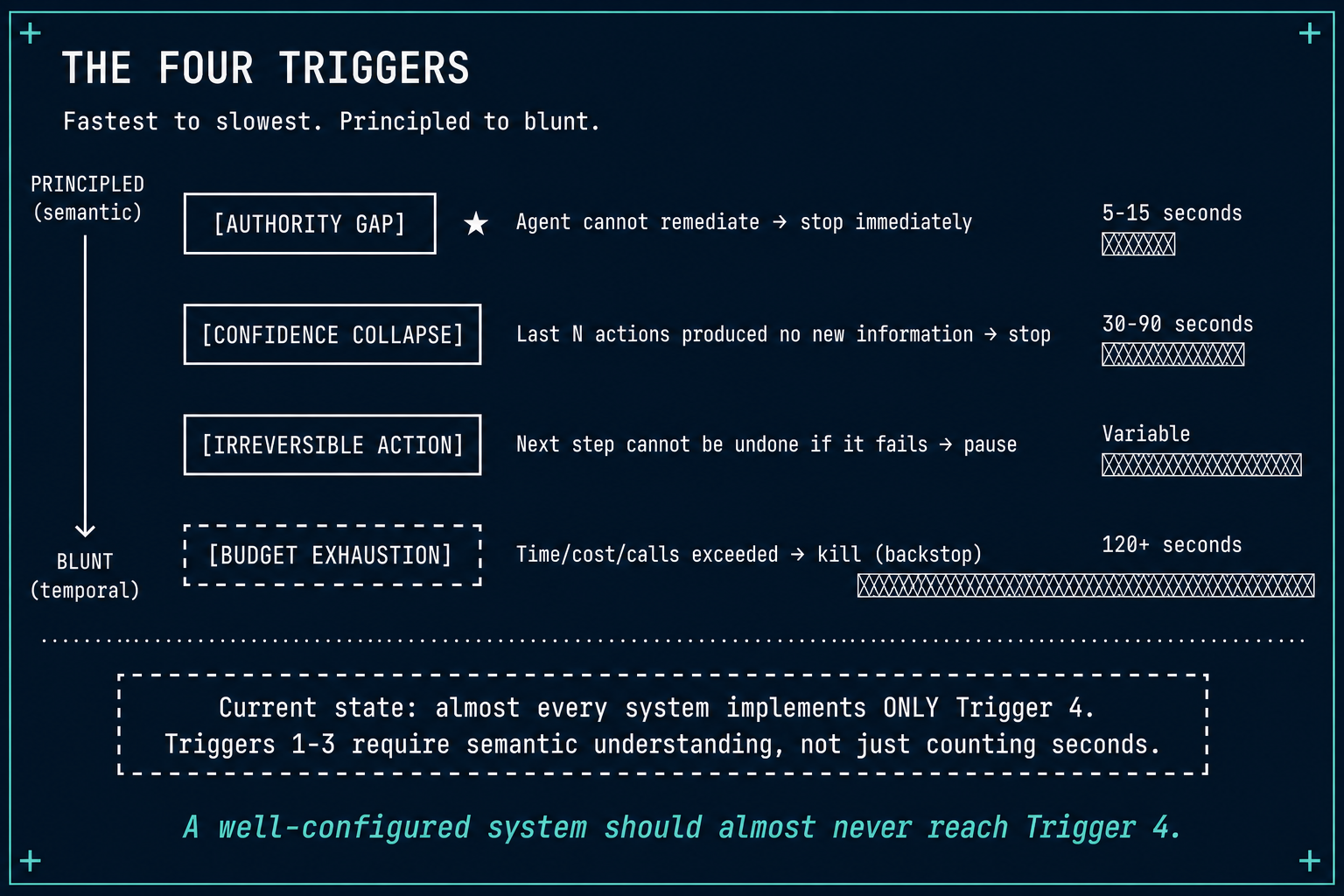
We formalize the patterns into four escalation triggers — four specific conditions under which continued execution is no longer justified:
| # | Trigger | What It Detects | When It Fires | Production Example |
|---|---|---|---|---|
| 1 | Authority Gap | Agent lacks remediation capability | On irremediable error classification | "Requires browser re-authorization" → stop |
| 2 | Confidence Collapse | New actions produce no new information | After N actions with no state change | Third script, same conclusion → stop |
| 3 | Irreversible Action | Next step cannot be compensated | Before the action executes | About to consume single-use refresh token → stop |
| 4 | Budget Exhaustion | Time, cost, or call-count exceeded | When limit is hit | 120s elapsed → stop regardless |
The ordering matters. Triggers 1–3 produce principled stopping decisions based on the nature of the situation. Trigger 4 is a blunt constraint that fires regardless of context.
From our production data:
- 1Authority GapWould have stopped all five error incidents within 2–14 seconds
- 2Confidence CollapseWould have stopped the working-tools investigation at ~20 seconds
- 3Irreversible ActionWould have prevented the token refresh attempt at minute 4
- 4Budget ExhaustionCaught 3 of 5 incidents — at 120 seconds, after 100+ seconds of waste
A well-configured system should almost never reach Trigger 4 — because Triggers 1–3 catch problems faster and for the right reasons.
Why "Ask When Uncertain" Fails
The most common escalation strategy in agent frameworks today is a prompt instruction: "If you're uncertain, ask the user."
This fails for two structural reasons.
Mechanism 1: Agents are never uncertain — and even when they are, it's not computable.
An LLM agent always has a next step. Given shell access, it can write a script. Given filesystem access, it can read a configuration file. Given MCP tools, it can call another API. The agent doesn't experience "uncertainty" — it experiences "I have more tools I haven't tried yet."
A timeout is computable: elapsed_seconds > 120. A call budget is computable: tool_calls > 15. "Uncertain" is not. How does the runtime evaluate whether an LLM is uncertain? Confidence scores are unreliable. Token probabilities don't correlate with correctness. Self-reported hedging language is ignored by the agent's own execution loop.
In Behavioral Induction, we showed this is capability-induced: the available tools shape the behavior. An agent with diagnostic tools will always find something to diagnose. Uncertainty never registers because diagnosis is always available.
Mechanism 2: Self-awareness is not a stopping condition.
From the Remediation Asymmetry post: the agent at minute 7:00 explicitly stated:
It correctly identified that it could not fix the problem. Then it continued investigating for another 2 minutes and 46 seconds.
The architectural lesson: escalation is not an agent decision. It is a gateway enforcement — what we call the Threshold Evaluator. The agent doesn't decide to stop. The system tells it to stop — by evaluating a runtime threshold that the agent cannot override.
The Threshold Inequality
The four triggers generalize into a single runtime decision function — an inequality evaluated after each action:
E[value of next action] > Risk + Cost + Irreversibility + Authority GapWhen the left side exceeds the right, continue. When the inequality flips — when E[value] of the next action drops below its combined cost — escalate.
Each term is computable at runtime:
| Term | What It Measures | How the Gateway Computes It |
|---|---|---|
| E[value] | Expected information gain or state change | Progress toward intent, novelty of proposed action, history of recent returns |
| Risk | Probability of making things worse | Tool-level metadata: can this action fail destructively? |
| Cost | Resources consumed by the action | Time, API calls, compute, token usage — all measurable |
| Irreversibility | Whether the action can be undone | Tool classification: reversible, idempotent, or irrevocable |
| Authority Gap | Whether remediation is possible | Error classification: retryable, self-remediable, or irremediable |
The inequality updates after every action. When the agent performs a read-back and confirms success, E[value] increases — the execution is making progress. When the agent runs a third script that produces the same conclusion as the first two, E[value] drops toward zero — the investigation is circular. When the gateway detects an irremediable error, Authority Gap dominates and the inequality immediately flips.
The four triggers are specific instances of this inequality flipping:
| Trigger | Why Inequality Flips |
|---|---|
| Authority Gap | Right side dominated by Authority Gap → instantly exceeds any E[value] |
| Confidence Collapse | E[value] drops to near-zero (no new information expected) |
| Irreversible Action | Irreversibility term spikes (action cannot be undone if it fails) |
| Budget Exhaustion | Cost term exceeds any possible E[value] (budget is gone) |
The Threshold Evaluator
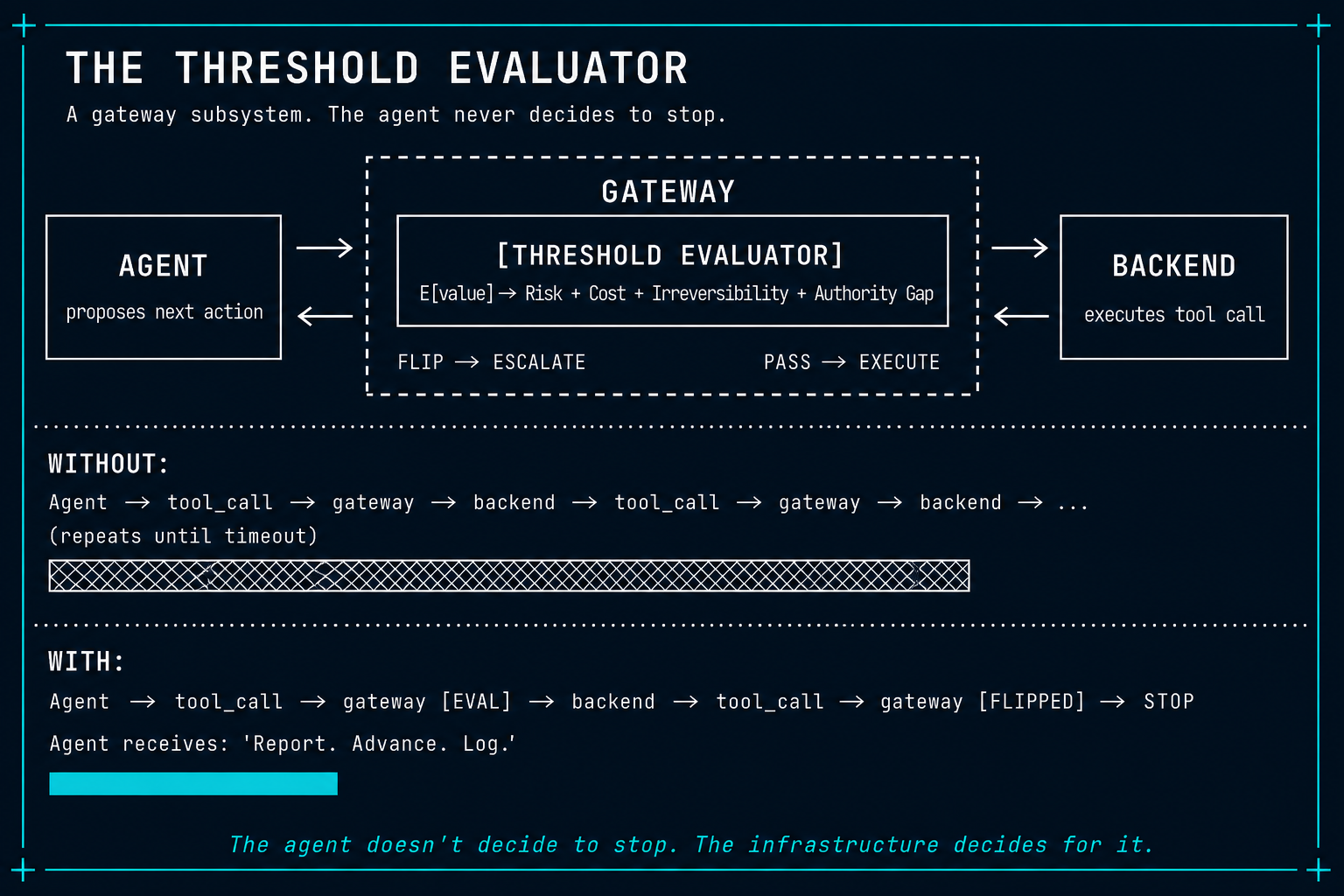
A principled threshold requires architectural support. The inequality is computed at the gateway, not by the agent — because agents demonstrably ignore their own conclusions about when to stop.
We call this runtime subsystem the Threshold Evaluator. It operates as a decision gate between the agent and the backend:
How it works
After each tool call, the Threshold Evaluator:
- 1Updates E[value]Did the last action produce new information? Did it change the world state? If the last 3 actions produced no state change, E[value] is decaying toward zero.
- 2Checks Authority GapDid the tool return an irremediable classification? If yes, the inequality flips immediately — no further evaluation needed.
- 3Accumulates CostTime elapsed, tool calls made, tokens consumed. All increment with each action.
- 4Evaluates IrreversibilityIs the proposed next action classified as irrevocable? If yes, and E[value] is not strongly positive, pause and seek approval.
- 5ComparesIf Risk + Cost + Irreversibility + Authority Gap > E[value], the Threshold Evaluator does not forward the next tool call. Instead, it returns an escalation signal.
What enforcement looks like
Without the Threshold Evaluator (current state):
Agent → tool_call → gateway → backend → response → agent → tool_call → ...
(repeats until timeout or human kills it)With the Threshold Evaluator:
Agent → tool_call → gateway [Threshold Evaluator] → backend → response →
Agent → tool_call → gateway [THRESHOLD FLIPPED] → ESCALATION →
Agent receives: "Stop. Report diagnosis. Advance to next task."
The agent never decides to stop. The infrastructure decides for it — the same way the irremediable classification from Remediation Asymmetry lives in the gateway, not in the prompt.
The Before/After
We don't need to hypothesize what threshold enforcement looks like. We already observed it — in the comparison between Gemini and Claude from the Behavioral Induction and Remediation Asymmetry posts.
Gemini (filesystem + shell + MCP tools, no threshold enforcement):
| Incident | Behavior | Stopped At |
|---|---|---|
| Gmail OAuth | Wrote scripts, inspected source, tested APIs | 120s (timeout) |
| Slack scope | Investigation spiral: wrote diagnostic scripts | 120s (timeout) |
| GDrive | Investigation spiral: inspected env vars | 120s (timeout) |
| Exa MCP | Wrote test_mcp.py, search_exa.py | 120s (timeout) |
| Working tools | Read source files before reporting success | 67s |
Claude (MCP tools only, implicit threshold via architecture):
| Incident | Behavior | Stopped At |
|---|---|---|
| Slack scope | "Unavailable — list_channels failed. Recommendation: Re-authorize." | ~5s |
| GDrive | Listed 5 files in a clean table | ~15s |
| Multi-service | Reported results per service, flagged failures | ~32s |
Claude's behavior IS threshold enforcement — just achieved through capability absence rather than runtime evaluation. When Claude encounters an irremediable error, it reports and advances. It doesn't have filesystem access to investigate further, so Trigger 1 (Authority Gap) is implicitly enforced by the capability boundary.
The architectural question: can you get Gemini's diagnostic capability with Claude's stopping behavior?
The answer is yes — with the Threshold Evaluator at the gateway. The agent keeps its capabilities (shell, filesystem, script writing). The gateway evaluates whether each action is justified. When the inequality flips, the gateway enforces stopping — regardless of what the agent wants to do next.
The Design Rule
"Is the next action justified?" is the question a threshold asks.
The first is a clock. The second is a decision.
Remediation Asymmetry established: Without an escalation boundary, giving an agent better tools for understanding problems makes it worse at responding to problems it cannot fix.
Escalation Thresholds makes this precise: a 120-second timeout still wastes 106 seconds on a problem the agent diagnosed in 14. The timeout is the right instinct — execution must be bounded. But it's the wrong abstraction — bounding by elapsed time ignores the semantics of what the agent is doing.
An agent that diagnoses correctly in 14 seconds and an agent making genuine progress at second 119 are treated identically by a timeout. One should stop immediately. The other should continue. Only the Threshold Evaluator — evaluating E[value] after each action — can distinguish between them.
Escalation Thresholds as a Design Primitive
Remediation Asymmetry asked: What happens when diagnosis exceeds remediation?
Escalation Thresholds asks: When exactly should the system stop?
The answer is not a number (120 seconds). It is not a prompt instruction ("ask when uncertain"). It is a runtime inequality that evaluates, after each action, whether continued execution is justified. When it isn't, the system escalates — not because a clock ran out, but because the expected value of further action flipped negative.
The causal chain connecting these primitives:
- 1Behavioral InductionCapabilities shape what the agent does
- 2Remediation AsymmetryWhen diagnostic capability exceeds remediation authority, the agent investigates indefinitely
- 3Escalation ThresholdsThe runtime mechanism that detects "indefinitely" and stops it — not with a clock, but with a decision boundary
The framework progression:
| Question | → | Primitive |
|---|---|---|
| Who is this agent? | → | Identity |
| What may it do on whose behalf? | → | Delegation |
| How is authority derived at runtime? | → | Permission Envelope Compilation |
| Does authority survive over time? | → | Constraint Durability |
| How do capabilities shape execution? | → | Behavioral Induction |
| What happens when diagnosis exceeds remediation? | → | Remediation Asymmetry |
| When should the agent stop? | → | Escalation Thresholds |
The Next Question
The threshold evaluates each action independently. Each step is checked: is this next action justified?
But consider: an agent makes 200 tool calls. Each individually passes the threshold — each has positive expected value, each is a small incremental step toward some goal. The Threshold Evaluator approves every one.
After 200 calls: 15 minutes elapsed. $47 in API costs. 500 customer records accessed. All for a task that should have required 5 calls and 30 seconds.
No single action was wrong. The total was unacceptable.
This is the gap between per-action thresholds and cumulative constraints. The threshold asks "should this ONE action continue?" The missing constraint asks "how much TOTAL execution is acceptable?"
Those are orthogonal questions. The threshold governs individual decisions. The budget governs accumulation. You need both. Neither alone is sufficient.
That question — how much total authority should one execution consume, even when every individual action is independently justified? — is the domain of Authority Budgets.
This is the nineteenth post in an ongoing series on AI agent trust architecture. Previous posts covered coordination integrity, instruction robustness, semantic irrevocability, governable execution, permission envelope compilation, constraint durability, behavioral induction, and remediation asymmetry. Escalation Thresholds is the first post in the governed execution arc: from diagnosing when agents should stop to building the full runtime architecture that governs autonomous execution.
References
- Agentic Abstention: Do Agents Know When to Stop Instead of Act? — Han et al., Jun 2026
- Knowing When to Quit: A Principled Framework for Dynamic Abstention in LLM Reasoning — Apr 2025
- LoopTrap: Termination Poisoning Attacks on LLM Agents — May 2025
- Agents of Chaos — Ullman, 2026
- CaRT: Teaching LLM Agents to Know When They Know Enough — Oct 2025
- R2V Agent: Teaching SLMs When to Ask for Help — May 2025
- Cost-Aware Speculative Execution for LLM-Agent Workflows — Jun 2026
- The Unfireable Safety Kernel: Execution-Time AI Alignment for AI Agents — Jun 2026
- Optimal Stopping vs Best-of-N for Inference Time Optimization — Kalayci, Raman, Dughmi, Oct 2025
- Act or Escalate? Evaluating Escalation Behavior in Automation with Language Models — Dani, Riegler, Feuerriegel, Apr 2025
- HiL-Bench: Do Agents Know When to Ask for Help? — Gu, Gao, Shi, Liu, Yang, Chen, Apr 2025
- Intelligence as Managed Autonomy: Failure, Escalation, and Governance for Agentic AI Systems — Rodríguez, May 2026
- Sequential Analysis: Hypothesis Testing and Changepoint Detection — Tartakovsky, Nikiforov, Basseville, 2014